Cross-posting the blog post that our CTO Hitesh Parashar wrote for "Machine Learning for Everyone" at "What Happens in a Machine Learning Project?".
Machine Learning follows a simple flow like a human brain to continuously enrich what the machine knows and applies it to make better decisions. It is a continuous refinement process since it keeps getting better with every learning iteration. The more data we feed to these iterations the better inferences the machine can make.
In this post we will walk you through the fundamentals of how a typical machine learning framework works.
There are primarily three stages in a machine learning project. First, it is the non-sexy part of machine learning where you bring in and prepare your data. Second, you experiment, train and evaluate your machine learning model (we will learn about the model in upcoming posts), and last but not the least you deploy your trained model to a production network to solve the problem you started with. The data coming out of the production deployment is fed back to our data wranglers to provide feedback and improve the model.
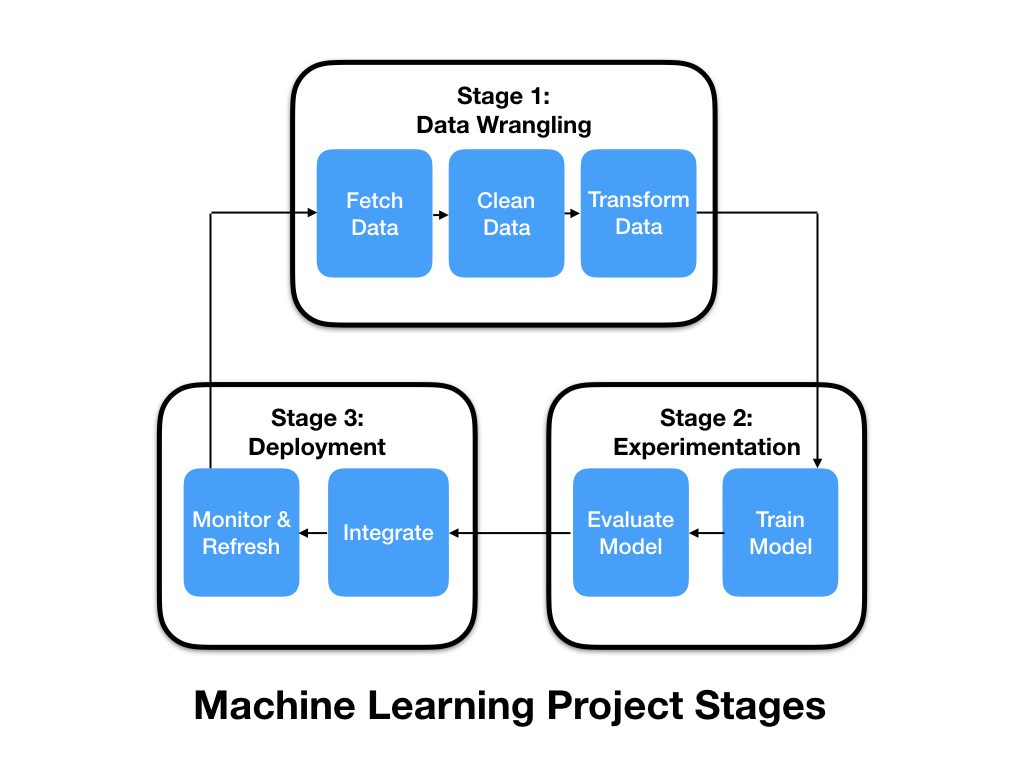
Let’s dig deeper into each one of these stages of a machine learning project by using the same example we started with in our first blog post to find out how much is my house worth?
Stage 1: Data Wrangling
There are three parts of data wrangling -
Fetch Data
Collecting data from myriad systems is not the most exciting part of a machine learning project. Your data typically lives in your data centers, or out in the world with your cloud hosted applications or partners. This is where you setup these connections with systems that contain the source data that you want to run your algorithms on. The more you automate collection of this data, the better it is since doing it manually, again and again is extremely boring and inefficient.
For our house prices example, we will go out and collect house price data along different attributes like square footage of homes, year of construction, location, school ranking, proximity to amenities, etc. This can be collected from recently sold homes or currently listed homes from organizations like MLS. Tactically, this will mean downloading or scraping files containing data in excel or comma separated value formats. Some organizations provide APIs (Application Programming Interfaces), that is a fancy way to call windows to their data.
Clean Data
What you get from your source data systems is not always ready for feeding to the rest of your pipeline. This is the stage where data scientists have to figure out the translation of raw, dirty, unusable data stream to what a machine can understand. They go through setting up rules that remove unwanted pieces of data and change the format of pieces that do not make sense in the current form.
The data that we collect for house prices, mostly, was meant for consumption by human beings or reasons other than analyses. Files that we collect always contain rows and columns of information not relevant or simply there since the format was not meant for consumption by a program. This stage includes scrubbing all of those unwanted pieces removed from the files that we will consume in later stages.
Transform data
In this stage you massage and bring the data elements close to what a machine learning algorithm can understand. Machine learning models are only as good as the data that is used to train them. A key characteristic of good training data is that it is provided in a way that is optimized for learning and generalization.
In the final stage of data wrangling for house prices, you convert data like prices in millions to dollars, addresses to geolocation coordinates, number of bath rooms in half as 2.5 or 3.5 instead of “2 and a half”. After these transformations, the data will be readable by our algorithms.
This data set is also divided into two parts at this stage, one part used for training and the other part used to verify if the machine learning algorithm actually learnt what it was supposed to.
Stage 2: Experimentation
After data is ready in a digestible format comes the heart of a machine learning project, training and evaluating models. What is a model by the way?
A model is the output that comes out of the training stage that captures the patterns that are used to answer your question.
Train model
In this stage you feed data to the training algorithm and out comes a modelthat captures the patterns in this data to answer your question. In this stage you also specify the training parameters that control this training process. You also take multiple passes over this data set that refine the model and find progressively better patterns.
Once our house prices data is massaged, it is passed to our learning algorithms. You also specify here training signals, for example, the number of passes to take through this data set, maximum size of the model, and ways to remove biases for extreme data sets (that multi-million dollar huge home sold recently in the neighborhood that was not the typical home around).
Evaluate model
After your model is output from the training stage, you need to make sure it actually is doing the job correctly. This stage is to find out the success or failure of the model. You need a new set of data which was not used for training to verify if the model produced is actually doing the right thing.
This is where we use the second part of the house prices data that was collected and separated out to verify the success of the algorithm. The model that was output from the training stage is now tested against this second dataset to make sure our machine did it’s job.
Stage 3: Deployment
Now that you have a trained and verified model you can use it to actually put it where it starts answering your questions. e.g. if we trained a model to answer a question whether a given email is spam or not then in this stage you will start including this model with your email clients to start separating out spam emails from the good ones.
Integrate
Training and evaluation of models happen in a vacuum, where the realtime data is not touching the machine learning algorithms. Integrating with actual system where this output will be used, is where you start doing things at a scale which requires response within certain time period to actually answer the question that we started with.
In case of our house prices example, integrating might mean putting this model to work within a website that predicts the value of your home given the address of the home.
Monitor & refresh
Machine learning is an iterative process. It does not end with just one cycle. You need to remain on top of how your algorithms are performing, debug and fix problems, make adjustments as needed to the training data that you used and keep feeding new scenario to the data wrangling team from your production environment. Refreshing data is the secret sauce of what makes machine algorithms getting better over time just like human beings do with the wisdom of having been in different situations multiple times.
Machine learning is all about striving to get better over time. By monitoring and annotating the accuracy and biases of predictions of house prices, data scientists feed this back to the data preparation and parameter tuning that makes these predictions get better iteration after iteration.
Conclusion
There is a pattern to how the machine learning projects are executed. It is very analogous to how human brain works by collecting, cleaning, analyzing and learning from the data around us. Most of the machine learning project involves hard, tedious and unglamorous work of data preparation, cleaning and transformation. Hope this blog post helped you get a sense of the pipeline that a typical machine learning project goes through.
In our future posts, we will take you through actual implementation of these steps and examples using frameworks like tensorflow, MXNet, Caffe and torch.
No comments.